
Summer School 2024

The DisAI Summer School on trustworthy, multilingual and multimodal AI will take place on September 3rd-6th at Kempelen Institute of Intelligent technologies in Sky Park Offices in Bratislava, Slovakia.
Join the community of experts and researchers in 3 selected fields of active research in AI: Trustworthy and explainable AI models, multilingual language models, and multimodal technologies. The school will feature introductory lectures and keynotes from leading experts in the fields. You will be able to present your current research to a group of international students that work on similar topics and international experts to obtain valuable feedback. Additionally, the summer school features a day on research ethics and transferable skills.
The summer school is organized within the scope of the DisAI project.
Programme
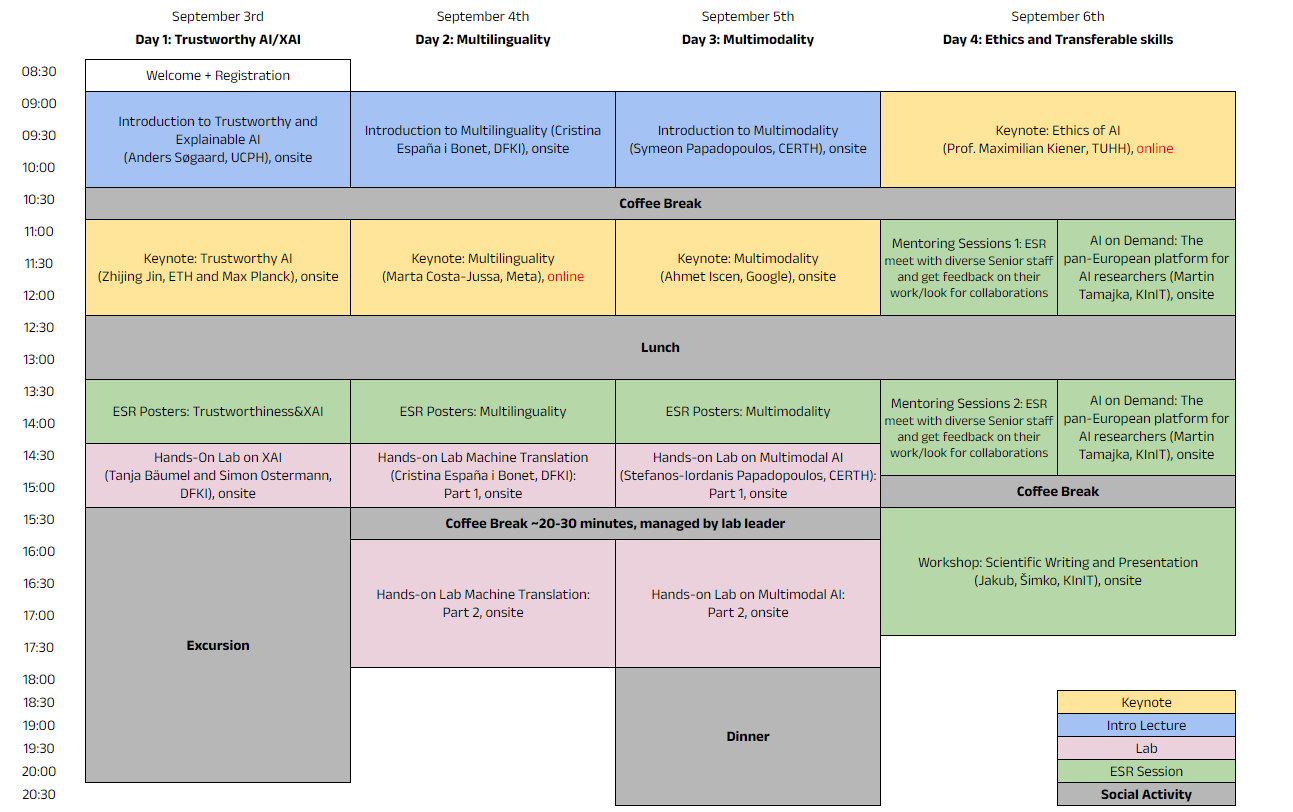
September 3rd
Day 1: Trustworthy AI/XA
| 8:30 – 9:00 | Welcome + Registration |
| 9:00 – 10:30 | Introduction to Trustworthy and Explainable AI (Anders Søgaard, UCPH), onsite |
| 10:30 – 11:00 | Coffee Break |
| 11:00 – 12:30 | Keynote: Trustworthy AI (Zhijing Jin, ETH and Max Planck), onsite |
| 12:30 – 13:30 | Lunch |
| 13:30 – 14:30 | ESR Posters: Trustworthiness & XAI |
| 14:30 – 15:30 | Hands-on Lab: XAI (Tanja Bäumel and Simon Ostermann, DFKI) |
| 15:30 – 19:00 | Excursion |
September 4th
Day 2: Multilinguality
| 9:00 – 10:30 | Introduction to Multilinguality (Cristina España i Bonet, DFKI) |
| 10:30 – 11:00 | Coffee Break |
| 11:00 – 12:30 | Keynote: Multilinguality (Marta Costa-Jussa, Meta), online |
| 12:30 – 13:30 | Lunch |
| 13:30 – 14:30 | ESR Posters: Multilinguality |
| 14:30 – 15:30 | Hands-on Lab: Machine Translation (Cristina España i Bonet, DFKI): Part 1, onsite |
| 15:30 – 16:00 | Coffee Break ~20-30 minutes, managed by lab leader |
| 16:00 – 18:00 | Hands-on Lab, Part 2, onsite |
September 5th
Day 3: Multimodality
| 9:00 – 10:30 | Introduction to Multimodality (Symeon Papadopoulos, CERTH), onsite |
| 10:30 – 11:00 | Coffee Break |
| 11:00 – 13:30 | Keynote: Multimodality (Ahmet Iscen, Google), onsite |
| 12:30 – 13:30 | Lunch |
| 13:30 – 14:30 | ESR Posters: Multimodality |
| 14:30 – 15:30 | Hands-on Lab: Multimodal AI (Stefanos-Ioardanis Papadopoulos, CERTH): Part 1, onsite |
| 15:30 – 16:00 | Coffee Break ~20-30 minutes, managed by lab leader |
| 16:00 – 18:00 | Hands-on Lab, Part 2, onsite |
| 18:00 | Dinner |
September 6th
Day 4: Ethics and Transferable skills
| 9:00 – 10:30 | Keynote: Ethics of AI (Maximilian Kiener, TUHH), online |
| 10:30 – 11:00 | Coffee Break |
| 11:00 – 13:30 | Mentoring Sessions 1: ESR meet with diverse Senior staff and get feedback on their work/look for collaborations In parallel: AI on Demand: The pan-European platform for AI researchers (Martin Tamajka, KInIT), onsite |
| 12:30 – 13:30 | Lunch |
| 13:30 – 15:00 | Mentoring Sessions 2: ESR meet with diverse Senior staff and get feedback on their work/look for collaborations In parallel: AI on Demand: The pan-European platform for AI researchers (Martin Tamajka, KInIT), onsite |
| 15:00 – 15:30 | Coffee Break |
| 15:30 – 17:30 | External Workshop: Scientific Writing and Presentation (Jakub Šimko, KInIT), onsite |
Speakers and Lecturers

Anders Søgaard, University of Copenhagen.
Professor in Natural Language Processing and Machine Learning at the University of Copenhagen. Jointly affiliated with the Dpt. of Computer Science, the Dpt. of Philosophy, the Pioneer Centre for Artificial Intelligence, and the Center for Social Data Science. Previously at University of Potsdam, Amazon Core Machine Learning, and Google Research. Father of three and a published poet.
Title: Introduction to Trustworthy and Explainable AI
Abstract: A 360 degree tour of XAI: What’s the tools in the toolbox, the scientific promise, the push from ethics, the legal initiatives, and, more importantly, what’s the deeper philosophical problems?

Zhijing Jin, ETH and Max Planck
Zhijing Jin (she/her) is a Ph.D. at Max Planck Institute & ETH. Her research focuses on socially responsible NLP by causal inference, developing Causal NLP methods to improve robustness, fairness, and interpretability of NLP models, as well as causal analysis of social problems. She has received 3 Rising Star awards, 2 PhD Fellowships, and was selected as a Young Scientist at the 73rd Lindau Nobel Laureate Meeting. Her work has been published at many NLP and AI venues (e.g., ACL, EMNLP, NAACL, NeurIPS, ICLR, AAAI), and featured in MIT News and ACM TechNews. She co-organizes 5 workshops (e.g., NLP for Positive Impact Workshop at EMNLP 2024, and Moral AI Workshop at NeurIPS 2023), leads the Tutorial on CausalNLP at EMNLP 2022, and served as the Publications Chair for the 1st conference on Causal Learning and Reasoning (CLeaR). To support diversity, she organizes the ACL Year-Round Mentorship Program. More information can be found on her personal website: zhijing-jin.com
Title: Causal Inference for Robust, Reliable, and Responsible NLP
Abstract: Despite the remarkable progress in large language models (LLMs), it is well-known that natural language processing (NLP) models tend to fit for spurious correlations, which can lead to unstable behavior under domain shifts or adversarial attacks. In my research, I develop a causal framework for robust and fair NLP, which investigates the alignment of the causality of human decision-making and model decision-making mechanisms. Under this framework, I develop a suite of stress tests for NLP models across various tasks, such as text classification, natural language inference, and math reasoning; and I propose to enhance robustness by aligning model learning direction with the underlying data generating direction. Using this causal inference framework, I also test the validity of causal and logical reasoning in models, with implications for fighting misinformation, and also extend the impact of NLP by applying it to analyze the causality behind social phenomena important for our society, such as causal analysis of policies, and measuring gender bias in our society. Together, I develop a roadmap towards socially responsible NLP by ensuring the reliability of models, and broadcasting its impact to various social applications.

Cristina España i Bonet, DFKI
Cristina España-Bonet is currently the machine translation team lead at the German Research Center for Artificial Intelligence (DFKI GmbH). With a background on physics (degree), artificial intelligence (master) and cosmology (PhD), she has been working on natural language processing at Universitat Politècnica de Catalunya (Barcelona), Saarland University and DFKI (Saarbrücken). Cristina is especially interested in interlingual and multilingual approaches and how these can be used to improve performance in low-resourced settings and for low-resourced languages. She is worried/interested about the underrepresentation of the non-dominant cultures in embeddings and language models and about the manipulation that large language models can exert on people. She has participated in 17 competitive funded projects (EU and Domestic) besides several industrial projects, knowledge transfer and dissemination activities. Cristina has 90+ scientific peer reviewed publications, has been teaching in the Physics, Computer Science and Computational Linguistics faculties and (co)advised 19 Master and 5 PhD students.
Title: Introduction to Multilinguality
Abstract: This lecture will give an overview of foundations of multilingual natural language processing, as well as details on the state of the art of cross-lingual and multilingual language models. We will focus on a range of multilingual and crosslingual tasks, as well as machine translation and other related topics.
Title: Hands-on Lab on Machine Translation
Abstract: The purpose of this lab is to train and evaluate a neural machine translation system (NMT) based on OpenNMT. We will use the pytorch version (OpenNMT-py) and train a system in Google Colab using a python notebook. We will also study the relevance of a throughout pre-processing and evaluation.

Marta Costa-Jussa, Meta
Marta R. Costa-jussà is a research scientist at Meta AI since February 2022. She received her PhD from the UPC in 2008. Her research experience is mainly in Machine Translation. She has worked at LIMSI-CNRS(Paris), Barcelona Media Innovation Center, Universidade de São Paulo, Institute for Infocomm Research (Singapore), Instituto Politécnico Nacional (Mexico), the University of Edinburgh and at Universitat Politècnica de Catalunya (UPC, Barcelona), co-leading the MT-UPC Group. She has received an ERC Starting Grant and two Google Faculty Research Awards . Recently, she has participated in the No-language-left-behind (NLLB) and Seamless projects. She has published hundreds of scientific papers and she is co-author of the novel El sueño de Mia.
Title: Multilinguality
Abstract: Beyond Semantic Evaluation in Seamless Speech Translation Models
In this talk, we will discuss various semantic and responsible evaluation methods that we have proposed for SeamlessM4T, a single model capable of handling speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation in up to 100 languages. We will focus on Blaser 2.0, an updated version of our evaluation tool that offers improved accuracy compared to its predecessor when it comes to quality estimation. Additionally, we will present our efforts to ensure the safety and responsibility of the model, including the implementation of a red-teaming system for detecting and mitigating added toxicity, as well as a systematic evaluation of gender bias.

Tanja Bäumel, DFKI
Tanja Bäumel is a researcher in the Multilinguality and Language Technology Lab at the German Research Center for Artificial Intelligence. She has a background in computational linguistics, computer science and cognitive science, and is currently pursuing her PhD. Her research is in the field of explainable artificial intelligence (XAI), where she works on understanding and interpreting the inner workings of large-scale pre-trained language models, as well as their limitations.
Title: Hands-on Lab on XAI
Abstract: In this hands-on lab, participants will get hands-on experience in methods of Explainable Artificial Intelligence (XAI), which aims to enhance the transparency and interpretability of AI models. In the lab, participants will be introduced to selected methods and practical approaches of XAI, that help users to understand and trust their models’ decisions. Participants will engage in interactive sessions utilizing common XAI tools on real-world datasets and scenarios. We will specifically focus on explainable AI methods for natural language processing. By the end of the lab, participants will have a robust understanding of XAI principles and be equipped with practical skills to apply XAI techniques in their own AI projects.

Simon Ostermann, DFKI
Simon Ostermann is lab manager, senior researcher and team lead at the Multilinguality and Language Technology lab at the German Research Center for Artificial Intelligence (DFKI). He holds a PhD in natural language processing from Saarland University (2020), on the role of general knowledge in the form of scripts in question answering. His research interests are in transparent and robust natural language processing; with the goal to (1) make the parameters and behaviour of language models more explainable and understandable and (2) to improve especially language models in terms of data consumption and size. He is coordinating and participating in diverse projects on the European and national level and a co-lead of the competence center on generative AI, established at DFKI in 2023.
Title: Hands-on Lab on XAI
Abstract: In this hands-on lab, participants will get hands-on experience in methods of Explainable Artificial Intelligence (XAI), which aims to enhance the transparency and interpretability of AI models. In the lab, participants will be introduced to selected methods and practical approaches of XAI, that help users to understand and trust their models’ decisions. Participants will engage in interactive sessions utilizing common XAI tools on real-world datasets and scenarios. We will specifically focus on explainable AI methods for natural language processing. By the end of the lab, participants will have a robust understanding of XAI principles and be equipped with practical skills to apply XAI techniques in their own AI projects.

Symeon Papadopoulos, CERTH
Dr. Symeon Papadopoulos is a Principal Researcher at the Information Technologies Institute, Centre for Research and Technology Hellas, Thessaloniki, Greece. He holds a PhD degree in Computer Science from the Aristotle University of Thessaloniki (2012) on the topic of Knowledge discovery from large-scale mining of social media content. His research interests lie at the intersection of multimedia understanding, social network analysis, information retrieval, big data management and artificial intelligence, where he has co-authored numerous journal articles, conference and workshop papers and book chapters. He has been participating in and coordinating a number of relevant EC FP7, H2020 and Horizon Europe projects in the areas of media convergence, social media and artificial intelligence. He is leading the Media Analysis, Verification and Retrieval Group (MeVer), and is a co-founder of the Infalia Private Company, a spin-out of CERTH-ITI.
Title of the talk: Introduction to Multimodal AI
Abstract: The talk will start by providing basic definitions of the main data modalities used in modern AI systems and will review a number of approaches for integrating different modalities in the design of an AI system. The talk will also present a number of relevant applications where multimodal AI is a key component.

Stefanos-Ioardanis Papadopoulos, CERTH
Stefanos-Iordanis Papadopoulos is a Research Associate at the Information Technologies Institute (ITI) of the Centre for Research & Technology Hellas (CERTH). As a member of Media Analysis, Verification and Retrieval Group (MeVer), he has been involved in several EU-funded projects. His main research interests lie in the areas of multimodal deep learning, focusing on multimedia verification and retrieval, such as automated multimodal misinformation detection and fact-checking, where he has co-authored several conference and journal articles.
Title: Hands-on Lab on Multimodal AI
Abstract: In this hands-on lab, we will delve into the fundamental concepts of multimodal deep learning. We will explore data preprocessing techniques, custom data loaders, neural network design and model training using Python and PyTorch. Participants will be called to implement and train deep learning models capable of detecting multimodal types of misinformation, namely out-of-context images and texts.

Ahmet Iscen, Google
Ahmet Iscen is a senior research scientist at Google. His area of expertise is developing methods for accurate and scalable image recognition in fine-grained, low-data and noisy-data settings, more recently using external tools and knowledge bases. His work has appeared in top-tier conferences, such as CVPR, ECCV, NeurIPS and ICLR . Previously, Ahmet worked as a postdoctoral researcher at Czech Technical University in Prague. He completed his Ph.D. degree at Université de Rennes I and Inria Rennes, and his PhD thesis received the Fondation Rennes 1 Best Thesis Award 2017 in the field of Mathematics, Sciences and Information and Communication Technologies.
Title of the talk: Fine-grained image recognition
Abstract: In this talk, I will present two of our recent works on fine-grained image recognition. In the first half of the talk, I will discuss how to equip existing vision-text models with the ability to refine their embedding with retrieved information from a knowledge memory at inference time, which greatly improves their zero-shot predictions. This is an alternative approach to encoding fine-grained knowledge directly into the model’s parameters; instead, we train the model to retrieve this knowledge from an external memory. In the second half of the talk, I will address web-scale visual entity recognition, specifically the task of mapping a given query image to one of the 6 million existing entities in Wikipedia. I will discuss our recent work “Generative Entity Recognition (GER)”, which, given an input image, learns to auto-regressively decode a semantic and discriminative “code” identifying the target entity.

Maximilian Kiener, TUHH
Maximilian Kiener is a Tenure-Track Professor of Philosophy and Ethics in Technology at Hamburg University of Technology, where he leads the Institute for Ethics in Technology (www.tuhh.de/ethics). He is also an Associate Member of the Faculty of Philosophy at the University of Oxford, and an Associate Research Fellow at The Institute for Ethics in AI at Oxford as well as the Oxford Uehiro Centre for Practical Ethics. Previously, Maximilian obtained the BPhil (2017) and DPhil (PhD) (2019) in Philosophy at the University of Oxford and worked as an Extraordinary Junior Research Fellow (2019-2021) and as a Leverhulme Early Career Fellow at Oxford (2021-2022). Maximilian specialises in moral and legal philosophy, with a particular focus on consent, responsibility, and artificial intelligence. More information can be found on his personal website: https://maximilian-kiener.weebly.com
Title of the talk: Deep Ethics
Abstract: Reinforcement learning (RL) is at the forefront of cutting-edge AI, showcasing remarkable achievements across a variety of domains, including autonomous mobility, robotics, health care, and finance. A fundamental assumption in many reinforcement learning models is that its so-called reward function can be scalarised: that is, diverse and potentially heterogeneous outcomes can be mapped onto a single and precise numerical value. In this talk, I explore how ethical considerations can be part of reward functions and already shape the training of AI systems. In particular, I outline a framework for how to integrate qualitative ethics, e.g. principles of autonomy, explainability, justice, and responsibility, into the quantitative metrics used in machine learning, thereby developing a methodology for what we may call ‘deep ethics’.

Jakub Šimko, KInIT
Jakub focuses on the intersection of human computation, machine learning, and data synthesis. He has recently been working on data augmentation techniques, social media algorithm auditing, and misinformation modeling. He promotes interdisciplinary approaches to computer science research. Recently, he has been dedicating considerable effort to preparation of Horizon Europe grant projects. Jakub works on multiple national and international research projects and participated in several industry projects. He co-authored more than 40 publications, received more than 500 citations. Jakub is enthusiastic about creating online educational materials and has authored over 50 educational videos with lectures or tutorials.
Title of the workshop: Scientific Writing and Presentation
Abstract: In this tutorial, we will address the most severe pain points pertaining to the fine craft of scientific paper writing and presentation preparation. Many researchers (not only young ones), struggle with these latter academic disciplines, undercutting the impact of good research work they do. The tutorial will cover audience considerations, writing of effective outlines (of both papers and presentations), decomposition of thoughts, writing of efficient front matter, covering up for reader/audience sloppiness, preventing writer’s block, and more. The content will draw from two excellent books by Michael Alley: The Craft of Scientific Presentations and The Craft of Scientific Writing. Reading of these books before the tutorial will maximize the knowledge gain.

Martin Tamajka, KInIT
Martin is a researcher and lead research engineer at the Kempelen Institute of Intelligent Technologies. He focuses on the research of new methods of deep learning, which includes current methods of natural language processing, as well as increasing the transparency of neural networks through explainability. He participated in and led industrial collaborations and research projects aimed, among other things, at creating a pan-European AI on Demand platform for AI researchers, analyzing historical cultural heritage with the help of artificial intelligence, or increasing the transparency of artificial intelligence models.
Title of the workshop: AI on Demand: The pan-European platform for AI researchers
Abstract: Although doing research in AI is an enjoyable endeavor, it also introduces certain challenges – getting access to sufficient computational resources, finding relevant datasets, or reproducing existing works, just to mention a few. AI on Demand is a pan-European platform (currently under development as a joint effort of multiple projects) that aims to help researchers do research more effectively and enjoyably. In the first part of this talk, we will introduce the platform, its components, and future directions. In the second part, we hope to collect your valuable feedback to enable you to influence the future development of AI on Demand.
Registration
Registration has been closed.
Schedule
- Register until: July 31, 2024
- Notification of acceptance: rolling basis; August 2nd, 2024 at latest
- Summer school: September 3rd-6th, 2024
Conditions and Eligibility
- Registration fee: None (Note: Accommodation and travel costs are not covered.)
- The summer school is open for anybody interested in the topic, primarily for the students (doctoral students, master students, early stage researchers). Understanding basics of AI and NLP is advantageous and recommended.
- Note: We reserve the right to decline some applications due to limited capacity and background fit.
Contact: summer.school@disai.eu
Organising team: Simon Ostermann, DFKI (programme), Katarina Hazyova, Marian Simko, KInIT (local organizers)
Venue
The summer school will be held in the Kempelen Institute of Intelligent Technologies (KInIT) in Bratislava, Slovakia. KInIT is an independent, non-profit institute dedicated to intelligent technology research. We bring together and nurture experts in artificial intelligence and other areas of computer science, with connections to other disciplines.
KInIT resides in the The Spot co-work space in the SkyPark Offices, a modern coworking and creative space adopted to support innovation and nurture community. The summer school will be held in the event rooms on the 6th floor (How to get here).
Bratislava lies in the south west part of Slovakia, accessible by plane, train and bus (Nivy bus station is located just 5 minutes from the KInIT). Vienna international airport with bus shuttle to Bratislava is a great option to reach for.
How to get here
KInIT office at SPOT on the 6th floor
The Spot, Sky Park Offices, Bottova 7939/2A, 811 09 Bratislava
Accommodation
Participants attending the Summer School are responsible for finding their own accommodation. We suggest using traditional ways to book accommodation for your stay (booking.com, airbnb.com).
Guest rooms in University Dormitories (limited number of available rooms):
ŠD Dobrovičova – check for more details and price list
ŠD Jura Hronca -check for more details and price list
More about Bratislava
Come and experience the atmosphere of the beautiful capital of Slovakia, Bratislava. The city is situated on the banks of the Danube River. Bratislava is a place with a rich cultural heritage, modern architecture and a vibrant atmosphere, making it an ideal location for our Summer School.
It is home to a number of Central Europe’s most prestigious universities and research institutions. The city’s academic environment fosters creativity and allows you to make new connections with inspiring young people. Bratislava is also a place for various cultural events and great nightlife! You are guaranteed to find the right spot for your cup of music and art. Affordable living costs and a robust public transport system make it easy for students to get around and enjoy all the city has to offer.
The city hosts numerous tech meetups and conferences, making it a hotspot for networking with industry professionals and fellow enthusiasts. Its growing startup ecosystem and investment in technology create endless opportunities for aspiring AI researchers.
Bratislava is close to the Austrian, Hungarian and Czech borders. The nearest European capitals are Vienna, Budapest and Prague. Join us in Bratislava this summer for an unforgettable experience combining history, culture and cutting-edge AI research.
See you in Bratislava!
For more information and tourist tips, visit this website: https://www.visitbratislava.com/
Social Events
Join us for social events organized during Summer School! These activities offer an opportunity to get to know other participants and experience Bratislava:
Tuesday, September 3rd from 16:00
Excursion: Boat Trip to Devin Castle: Join us for a boat ride to the historic Devin Castle (finger food and soft drinks included). Explore the castle grounds and enjoy a wine-tasting session featuring local black currant wines, accompanied by a small snack. We will return to the city centre by boat at 20:30.
Estimated time plan:
- start at 16:00
- cruise to Devin 16:00 – 17:30
- castle excursion 18:00 – 19:00
- wine tasting 19:00 – 20:00
- return to city center 20:30
Thursday, September 5th after 18:00
Dinner: Enjoy a pleasant dinner in the city centre with fellow participants. A selection of the restaurant’s bestsellers will be served together with soft drinks, beer and wine.
Reservation details: start at 18:30, Mestiansky pivovar, street Dunajska 21, Bratislava